Biology and computer science often get framed as two separate poles. The standard narrative is that computer science gave biology its tools. The clinician sequences the tumour, the epidemiologist collects the cohort, and then they hand it off to a computer scientist to actually build the prediction model.
That story is incomplete. The deeper truth is that biology’s hardest problems have repeatedly demanded new computational methods, and those methods then spread everywhere else.
Biology has always pushed computation forward
Enter Margaret Dayhoff. It was 1965 when she compiled the first protein sequence database: 65 sequences, published as the Atlas of Protein Sequence and Structure. To compare those sequences she needed a scoring system, so she built the PAM substitution matrix, one of the earliest statistical models of molecular evolution [1]. She also invented the single-letter amino acid code just to fit sequence data onto punch cards. Biology didn’t borrow computer science. It improvised its own.
Five years later, Needleman and Wunsch needed to align protein sequences and brought dynamic programming into biology [2]. The algorithm existed in mathematics, but the reason to use it came from a biological question nobody else was asking. Smith and Waterman refined it in 1981 [3]. BLAST made it scalable in 1990 [4]. Each step driven by the same pressure: biological data growing faster than anyone could analyse by hand.
Hallam Stevens documents this beautifully in Life Out of Sequence [5]. His central observation: biology adapted itself to the computer, not the other way around. Biologists learned to program, built databases, invented algorithms. The questions wouldn’t wait.
The cloud lab: compute in one city, wet lab in another
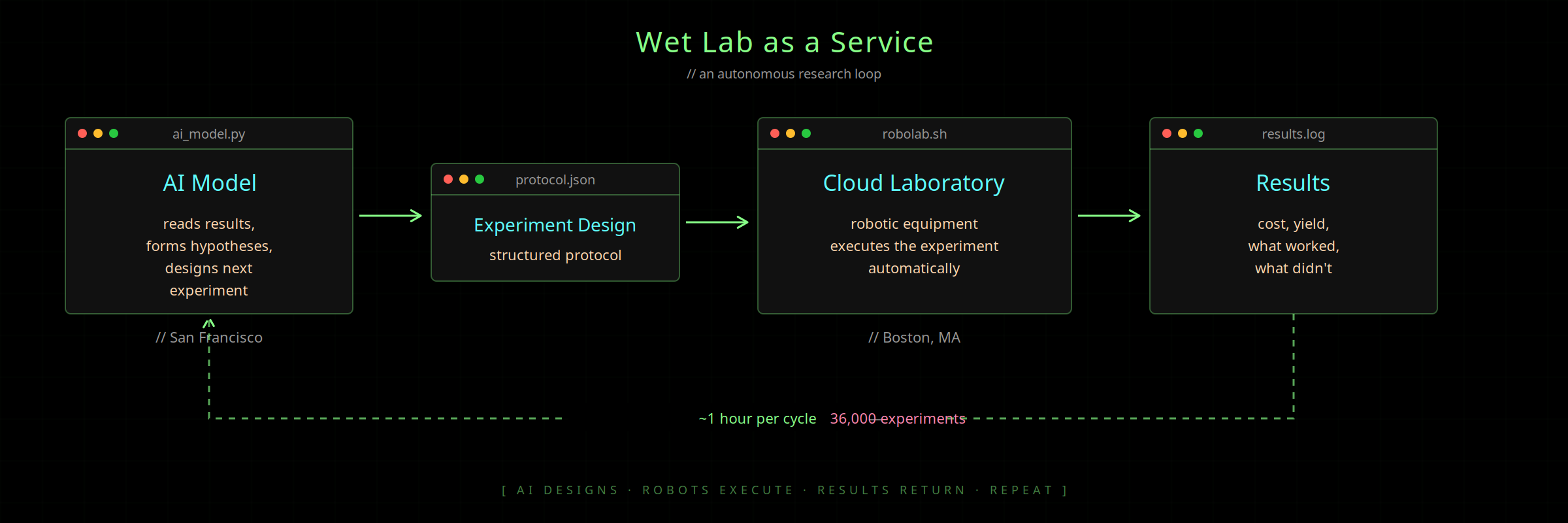
Fast-forward to February 2026. OpenAI and Ginkgo Bioworks announced that GPT-5 had autonomously designed, executed, and learned from 36,000 biological experiments, without a human deciding which reagent to try next [6][7].
The setup is cloud computing applied to biomedicine in the most literal sense: compute in one city, wet lab in another, connected by an API. GPT-5 in San Francisco reads results, forms hypotheses, designs reactions, and sends instructions over the network to robotic equipment in Boston. One hour per cycle, six rounds total. The target was cell-free protein synthesis, and the result was a 40% cost reduction over Stanford’s best published benchmark [7].
The architecture is the same as any distributed cloud service: structured requests, remote execution, programmatic feedback loops. OpenAI built the interface using a Pydantic schema to validate every experiment before the robots touched anything. The model wasn’t suggesting ideas. It was submitting executable protocols as API calls.
“You need models paired with labs that can do the experimental validation.” — Reshma Shetty, Ginkgo Bioworks [6]
Ginkgo launched its Cloud Lab in March 2026, starting at $39 per run [6]. The U.S. Department of Energy is funding a 97-robot autonomous lab at PNNL, built by Ginkgo, expected to be operational by 2030 [6].
Why this matters
Dario Amodei argues in Machines of Loving Grace [8] that biology is where AI will have its largest near-term impact. His metaphor is vivid: “a country of geniuses in a datacenter” working on every open problem in biology at once [8]. OpenAI’s GPT-Rosalind [9], a reasoning model optimized for biology, drug discovery, and experimental planning, is an early move in that direction.
But the future probably won’t look like Ginkgo’s showcase. It never does. Sequencing went from billion-dollar genome centres to a MinION you plug into a USB port. The pattern is always the same: an expensive, centralised technology appears, and then scientists make it small, cheap, and theirs.
Cloud laboratories will follow that arc. Nobody in 1965 expected a biochemist to be programming in the middle of the night. But Dayhoff did it because the science required it. Today, no one blinks when a biologist writes Python or runs a pipeline. That shift happened because scientists walked toward the problem, not because computer science reached out.
The same will be true of the cloud lab. Designing experiments through an API, running reactions on hardware you never touch, iterating in hours instead of months. It won’t feel like computer science. It will just feel like science.
References
- Dayhoff, M.O. et al. (1978). “A model of evolutionary change in proteins.” Atlas of Protein Sequence and Structure, 5(3), 345–352.
- Needleman, S.B. & Wunsch, C.D. (1970). “A general method applicable to the search for similarities in the amino acid sequence of two proteins.” Journal of Molecular Biology, 48(3), 443–453.
- Smith, T.F. & Waterman, M.S. (1981). “Identification of common molecular subsequences.” Journal of Molecular Biology, 147(1), 195–197.
- Altschul, S.F. et al. (1990). “Basic local alignment search tool.” Journal of Molecular Biology, 215(3), 403–410.
- Stevens, H. (2013). Life Out of Sequence: A Data-Driven History of Bioinformatics. University of Chicago Press.
- “OpenAI and Ginkgo Bioworks show how AI can accelerate scientific discovery.” Scientific American, March 2026.
- Smith, A.A. et al. (2026). “Using a GPT-5-driven autonomous lab to optimize the cost and titer of cell-free protein synthesis.” bioRxiv, 10.64898/2026.02.05.703998.
- Amodei, D. (2024). “Machines of Loving Grace.”
- “Introducing GPT-Rosalind for life sciences research.” OpenAI, April 2026.